LLM 训练显存估算全指南:从 ZeRO 到 MoE
本文是我在研究 LLM 训练显存开销过程中的系统性梳理,从 ZeRO 论文的 16 Φ bytes/param 公式出发,逐步拆解激活值、DataLoader、冻结层、LoRA,最后延伸到 MoE 架构的特殊性。每一部分都尽量给出可量化的公式和真实 case,方便直接用于工程估算。
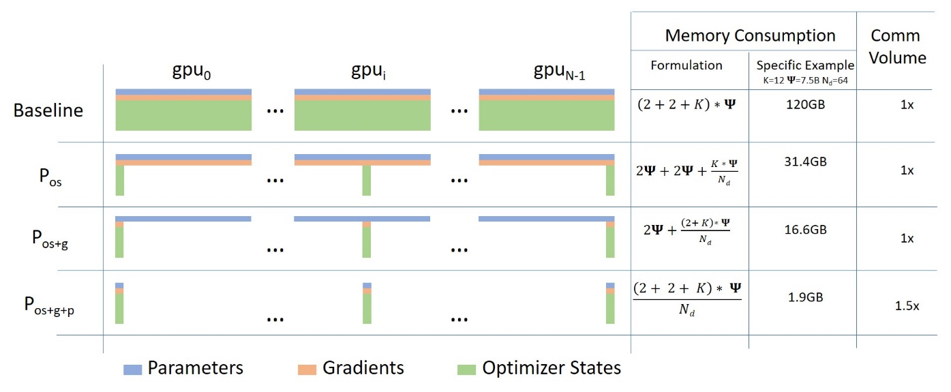
一、基础:ZeRO 的 16 bytes/param 从何而来
ZeRO 论文的核心研究问题是:Model States 为什么无法放进单卡,以及如何切分它?
分析对象是那些与参数量 Φ 成严格正比、可精确量化的部分,统称 Model States:
| 组成部分 | 精度 | 每参数字节数 |
|---|---|---|
| 参数(Parameters) | fp16 | 2 |
| 梯度(Gradients) | fp16 | 2 |
| 优化器状态 - 参数副本 | fp32 | 4 |
| 优化器状态 - 一阶矩 m | fp32 | 4 |
| 优化器状态 - 二阶矩 v | fp32 | 4 |
| 合计 | 16 bytes/param |
Model States 显存 = Φ × 16 bytes
对于 LLaMA-7B(Φ = 7B):
参数 fp16:7B × 2 = 14 GB
梯度 fp16:7B × 2 = 14 GB
优化器 fp32:7B × 12 = 84 GB
Model States 合计:112 GB
二、ZeRO 为什么不考虑激活值
激活值被 ZeRO 论文归类为 Residual Memory States,有意排除在 16 bytes 公式之外,原因很直接:
激活值不是参数量的函数。 它依赖一堆运行时超参数:
Activation ∝ f(b, s, h, a, layers)
b 和 s 每次跑实验都可能改变,
根本无法像 16Φ 那样给出一个"固定系数 × 参数量"的简洁表达
ZeRO 的核心贡献是设计切分 Model States 的通信协议,需要一个精确的、只依赖 Φ 的公式。激活值通过 Activation Checkpointing 独立处理,属于正交的优化维度。这是刻意的 scope 决策,不是遗漏。
三、激活值显存:逐操作拆解
符号定义
b = batch size
s = sequence length
h = hidden dimension
a = attention heads
Self-Attention 部分
每一步的输出张量都要缓存用于计算梯度:
| 操作 | 保存的张量 | 显存(bytes) |
|---|---|---|
| LayerNorm 输入 x | (b, s, h) | 2bsh |
| Q, K, V 投影后 | (b, s, h) ×3 | 6bsh |
| Attention Score QKᵀ/√d | (b, a, s, s) | 2bas² |
| Softmax 输出 P | (b, a, s, s) | 2bas² |
| Dropout mask | (b, a, s, s) | bas²(bool) |
| Attention Output PV | (b, s, h) | 2bsh |
| 输出投影后 | (b, s, h) | 2bsh |
Attention 小计:
≈ 10bsh + 5bas²
FFN 部分
| 操作 | 保存的张量 | 显存(bytes) |
|---|---|---|
| LayerNorm 输入 | (b, s, h) | 2bsh |
| 第一个线性层输出 | (b, s, 4h) | 8bsh |
| GeLU/SiLU 激活输出 | (b, s, 4h) | 8bsh |
| 第二个线性层输出 | (b, s, h) | 2bsh |
FFN 小计:
≈ 20bsh
单层合计
per_layer = 2 × (30bsh + 5bas²)
= 60bsh + 10bas² bytes
这就是 ZeRO 论文那个公式的来源:s × b × h × (34 + 5as/h),系数略有差异是因为论文用 Post-LN 结构并忽略了部分小项。
7B 数值代入(b=1, s=2048, h=4096, a=32, L=32)
线性项:60 × 1 × 2048 × 4096 = 503 MB / layer
Attn Score 项:10 × 1 × 32 × 2048² = 1342 MB / layer
单层激活 ≈ 1.8 GB
32 层合计 ≈ 57 GB(不用 checkpointing)
注意 attention score 项是 s 的平方,长序列时会爆炸:
s=2048 → 8.6 GB(仅 attn score,32 层)
s=4096 → 34 GB(4 倍增长)
四、激活值的两大救星
Gradient Checkpointing
不保存所有层的激活值,只在 checkpoint 位置保存,反向传播时重新跑前向还原:
全保存: 32 × 1.8 GB = 57 GB
每层 checkpoint:只保存层边界输入 x = 32 × 16 MB ≈ 0.5 GB
代价:多算一次前向,训练时间增加约 30-40%
Flash Attention
改变 attention score 的存储方式:
普通 Attention:保存完整 (b, a, s, s) 矩阵 → O(s²) 显存
Flash Attention:分块计算,只保存 log-sum-exp 统计量 → O(s) 显存
消除 attn score 项后(7B):
单层激活 ≈ 503 MB → 32 层 ≈ 16 GB
Flash Attention + Gradient Checkpointing 叠加:
激活值降到 1-3 GB,代价仅 30% 计算时间
这也解释了为什么工程实践中 ZeRO 的 16 bytes 估算”够用”——现代训练栈默认开这两个优化,激活值可以忽略,16 bytes 的误差范围能覆盖它。长序列不开 Flash Attention 时例外。
五、把激活值纳入统一公式
为了和 16 bytes 公式统一,把激活值也表达成「每参数 α bytes」的形式。
每层参数量约为 Φ ≈ L × 12h²,激活值总量为 A = L × bsh(60 + 10as/h),因此:
α = A / Φ = (bs/h) × (5 + 5as/6h)
Total Memory = Φ × (16 + α) bytes
7B 代入验证:
α = (1 × 2048 / 4096) × (5 + 5 × 32 × 2048 / 24576)
= 0.5 × (5 + 13.65) ≈ 9.3 bytes/param
激活显存验证:7B × 9.3 ≈ 65 GB(与直接算的 57 GB 量级吻合)
总显存:7B × (16 + 9.3) ≈ 177 GB
不同配置下的 α 修正:
| 配置 | α 近似值(7B,b=1,s=2048) |
|---|---|
| 无优化 | ~9.3 |
| Flash Attention | ~2.5(消除 s² 项) |
| Grad Checkpointing | ~0.05 |
| 两者叠加 | ~0.01(退化回 16 bytes 公式) |
六、冻结层训练的显存计算
冻结层意味着不需要计算参数梯度,不需要优化器状态,但参数本身仍在显存中:
冻结层:只保留 fp16 参数 → 2 bytes/param
训练层:保留完整训练状态 → 16 bytes/param
7B 冻结 50%(3.5B 参数):
冻结层显存 = 3.5B × 2 = 7 GB
训练层显存 = 3.5B × 16 = 56 GB
Model States 合计 = 63 GB(相比 112 GB 节省约 44%)
⚠️ 激活值的特殊情况
冻结层虽然不需要参数梯度,但如果训练层在冻结层之后,反向传播仍需穿越冻结层计算激活梯度:
冻结前半部分层(底层)→ 反向仍需穿越 → 激活值显存几乎不减少
冻结后半部分层(顶层)→ 反向不经过 → 激活值可以节省
七、LoRA 训练显存计算
LoRA 核心:冻结原始权重 W,只训练低秩矩阵 A 和 B:
ΔW = B × A, A ∈ R^{d×r},B ∈ R^{r×k},r << d,k
LoRA 参数量
以 7B 模型(h=4096,L=32,r=8,作用于 Q/K/V/O):
每层 LoRA 参数:4 × (4096×8 + 8×4096) = 4 × 65536 ≈ 0.26M
32 层合计 ≈ 8M(约为 7B 的 0.1%)
实际上视具体实现也常在 25M 上下,这里取保守值。
显存构成
原始模型权重(冻结,fp16):7B × 2 = 14 GB
LoRA 参数(fp16): 25M × 2 ≈ 0.05 GB
LoRA 梯度(fp16): 25M × 2 ≈ 0.05 GB
LoRA 优化器状态(fp32): 25M × 12 ≈ 0.3 GB
⚠️ LoRA 激活值的常见误解
反向传播仍然需要穿越所有冻结层来计算 LoRA 分支的梯度,激活值显存并不会减少:
LoRA 不用 gradient checkpointing:
14 GB + 0.4 GB + 30 GB(激活)≈ 44 GB
LoRA + gradient checkpointing:
14 GB + 0.4 GB + 3 GB ≈ 17-18 GB ✅ 单张 A100 80G 可以跑
LoRA 最大的节省来自优化器状态(84 GB → 0.3 GB),而不是激活值。激活值是 LoRA 最容易被忽视的大头。
三种训练方式汇总(7B)
| 训练方式 | 参数显存 | 梯度+优化器 | 激活值 | 总计(约) |
|---|---|---|---|---|
| 全量训练 | 14 GB | 98 GB | 30 GB | ~144 GB |
| 冻结后 50% 层 | 14 GB | 49 GB | ~25 GB | ~88 GB |
| LoRA (r=8) | 14 GB | 0.4 GB | 30 GB | ~44 GB |
| LoRA + GradCkpt | 14 GB | 0.4 GB | 3 GB | ~18 GB |
八、DataLoader 对显存的影响
结论先行
DataLoader 本身对 GPU 显存的影响可以忽略。
DataLoader 的 prefetch 和 batch 主要占用 CPU RAM,只有 .to(device) 之后才转移到 GPU 显存,而 token 是离散整数,远比 fp16 激活值小:
单个 batch 输入显存:
input_ids: b × s × 4 bytes
attention_mask: b × s × 1 bytes
labels: b × s × 4 bytes
合计 ≈ b × s × 13 bytes
b=32, s=4096:32 × 4096 × 13 ≈ 1.6 MB ← 可以忽略
真正需要关注的:显存 Spike
实际工程中 OOM 往往不是平均占用超了,而是瞬间峰值超了。
Vocab Logits 是最容易被忽视的 spike:
Logits tensor shape:(b, s, vocab_size)
现代 LLM vocab 越来越大:
LLaMA-2: 32,000
LLaMA-3: 128,256 ← 4 倍于 LLaMA-2
Qwen2: 152,064
LLaMA-3,b=4,s=4096,fp32:
4 × 4096 × 128256 × 4 bytes ≈ 8.4 GB ← 相当可观,必须显式计算
其他 spike 来源:
- Forward 结束、Backward 开始前:激活值 + 当前层梯度同时存在,峰值约为激活值的 1.5x
- Optimizer step 时:fp32 参数副本更新完,旧的还没释放,短暂双份参数
- CUDA 显存碎片化(fragmentation):PyTorch 的 caching allocator 持有已释放的显存块,实测可导致额外 5-10% 的”账面占用”,可通过
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True缓解
完整估算模板
def total_memory_estimate(phi_B, b, s, h, a, layers, vocab_size,
use_flash=True, use_ckpt=True):
# Model States
model_states = phi_B * 1e9 * 16
# Activation
if use_flash and use_ckpt:
activation = 0
elif use_flash:
activation = layers * 60 * b * s * h * 2
else:
activation = layers * (60*b*s*h + 10*b*a*s*s) * 2
# Logits spike(不能忽略!)
logits = b * s * vocab_size * 4
# Safety buffer 10%
subtotal = model_states + activation + logits
return subtotal * 1.1 / 1024**3
# LLaMA-3 7B, b=2, s=4096
# ≈ (112 GB + 0 + 4.2 GB) × 1.1 ≈ 127 GB
显存预留系数建议
| 场景 | 额外预留 | 说明 |
|---|---|---|
| 文本 LLM 训练 | +10% | 主要 cover spike 和 CUDA context |
| 大 vocab(>100K) | +10% + Logits 显式计算 | LLaMA-3/Qwen 必须单独算 |
| 多模态训练 | +15~20% | 图像/视频 feature 更大 |
| 长序列(s>8K) | +15% | attention 计算中间态 spike |
| 梯度累积步数>1 | 不额外增加 | 每步 batch 大小不变 |
九、MoE 模型训练显存:以 Qwen3-30B-A3B 为例
MoE 的核心陷阱
Dense 模型:Φ_active = Φ_total,直接用 16 × Φ_total 估算。
MoE 打破了这个等式:
Qwen3-30B-A3B:
Φ_total = 30B(所有专家都要加载进显存)
Φ_active = 3B(每个 token 只激活这么多参数)
但训练时,所有 30B 的梯度和优化器状态都必须存在。
因为 routed expert 的权重在不同 step 被不同 token 激活,每个专家都需要积累梯度和维护完整的优化器状态(m, v),否则某个专家某一步没被激活,它的 m/v 就丢失了。
Qwen3-30B-A3B 架构参数
num_hidden_layers = 48
hidden_size (h) = 2048
num_attention_heads = 32,head_dim = 128
num_key_value_heads = 8 (GQA)
ffn_dim_per_expert = 1024
num_experts = 128
num_experts_per_tok = 8 (top-8 routing)
shared_experts = 1 (每层永远激活,dim=4096)
vocab_size = 151,936
参数量验证:
Attention per layer(GQA):
Q:2048×2048 = 4.2M
KV:2048×2048 = 4.2M(GQA 极大减少 KV 参数)
O:4.2M
≈ 12M / layer
Routed Expert FFN per layer:
128 experts × (2048×1024 + 1024×2048) × 2 ≈ 512M / layer
Shared Expert per layer:
(2048×4096 + 4096×2048) × 2 = 32M / layer
48 层 + Embedding:
48 × (12+512+32)M + 1.2B ≈ 27.4B ≈ 30B ✓
Active params 验证(per token):
12M(attn)+ 8×4M(top-8 experts)+ 32M(shared)= 76M / layer
48 layers:76M × 48 ≈ 3.65B ≈ 3B(A3B 得名于此)✓
Model States:按 Φ_total 计算
全量训练(混合精度 + Adam):
Model States = 30B × 16 bytes = 480 GB
⚠️ 用 Φ_active = 3B 估算是严重错误,会低估 10 倍
激活值:按 Active 路径计算
这是 MoE 真正享受 sparsity 红利的地方。
Attention 激活(GQA 下):
Flash Attention 开启时,per layer:
≈ 60bsh = 60 × 1 × 2048 × 2048 = 251 MB
(GQA 的 kv_heads=8 远小于 32,attn score 项本来就小)
Expert FFN 激活(关键差异):
Router logits:(b, s, num_experts) = 1 × 2048 × 128 × 2 = 0.5 MB
Gate scores: (b, s, top_k) = 1 × 2048 × 8 × 4 = 0.064 MB
Routed Expert 中间激活(只算 8 个 expert):
b × s × top_k × ffn_dim × 2 × 2 = 1 × 2048 × 8 × 1024 × 4 = 64 MB
Shared Expert 中间激活:
b × s × 4096 × 4 = 32 MB
Expert FFN 合计 ≈ 96 MB / layer
单层激活:
251 MB(attention)+ 96 MB(MoE FFN)= 347 MB
48 层合计:347 × 48 ≈ 16.7 GB
对比同等 active 参数量的 Dense 3B 模型激活值(约 10-15 GB),MoE 和它相近,这符合直觉:激活值只跟计算路径有关。
MoE 特有的额外显存开销
Expert Parallelism(EP)通信缓冲区:
MoE 训练通常使用 EP,不同 GPU 持有不同专家,需要 All-to-All 通信:
EP=8(每 GPU 持有 128/8=16 个专家),b=1, s=2048, top_k=8:
capacity_per_rank = 1 × 2048 × 8 / 8 = 2048 tokens
buffer = 8 × 2048 × 2048 × 2 bytes × 2(双向)≈ 256 MB
Auxiliary Load Balance Loss:
Router probability per layer:(b, s, num_experts) fp32 = 1 MB / layer
48 层合计 ≈ 48 MB(可忽略)
完整显存汇总(b=1, s=2048, Flash Attn,无 GradCkpt)
① Model States(Φ_total = 30B): 480 GB
② 激活值(active 路径): 16.7 GB
③ Logits spike: 1 × 2048 × 151936 × 4 ≈ 1.2 GB
④ EP 通信缓冲区: ≈ 0.3 GB
⑤ CUDA Context + 碎片: ≈ 2 GB
小计:≈ 500 GB
× 1.10 安全系数 ≈ 550 GB
与 Dense 30B 对比
Dense 30B:
Model States:480 GB
激活值(h=7168,32 layers):≈ 50-80 GB
合计:≈ 560 GB
MoE 30B-A3B:
Model States:480 GB(相同!)
激活值:≈ 17 GB(远小于 Dense)
合计:≈ 500 GB
MoE 的节省完全体现在激活值上,Model States 按 Φ_total 算,不因 sparsity 减少。
实际训练并行策略(8×H100 80GB = 640GB)
ZeRO-3 切分 Model States:
480 GB / 8 = 60 GB / GPU
Flash Attention + Grad Checkpointing:
激活值:17 GB → ~2 GB
EP=8 通信 buffer:~0.3 GB
单卡实际占用:
60 + 2 + 0.3 ≈ 62 GB ✅ 单张 H100 80GB 可以训练!
仅用 EP=8,不用 ZeRO-3:
480 GB 无法切分 → 直接 OOM
十、统一估算公式总结
综合所有章节,完整的训练显存估算公式为:
Total = 16 × Φ_total ← Model States,永远用总参数量
+ α × Φ_active ← 激活值,按 active 路径
+ b × s × vocab_size × 4 ← Logits spike,显式计算
+ EP_buffer ← MoE 专用,约 0.3 GB
+ 1 GB ← CUDA Context 固定开销
× 1.10 ~ 1.15 ← 安全系数(碎片化 + spike)
其中 α:
无优化: ~9.3 bytes/param(7B,s=2048)
Flash Attention: ~2.5
Grad Checkpointing: ~0.05
两者叠加: ~0.01(可忽略,退化回 16 bytes)
对于 MoE,激活值系数还需加入 router overhead:
α_moe ≈ α_dense × 1.15(router 带来约 15% 额外激活开销)
核心结论一句话:用 Φ_total 算 Model States,用 active 路径算激活值,别忘了 Logits spike,留 10% 安全余量。
参考文献
ZeRO 系列论文
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models — Rajbhandari et al., 2019. ZeRO 原始论文,16 bytes 公式来源,必读。
- ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning — Rajbhandari et al., 2021. ZeRO-3 扩展到 NVMe,讨论了 Residual States 的处理。
- ZeRO-Offload: Democratizing Billion-Scale Model Training — Ren et al., 2021.
激活值与显存优化
- Reducing Activation Recomputation in Large Transformer Models — Korthikanti et al., 2022. Megatron-LM 团队对激活值逐 op 的精确分析,本文拆解公式的主要参考。
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness — Dao et al., 2022.
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning — Dao, 2023.
- Training Deep Nets with Sublinear Memory Cost — Chen et al., 2016. Gradient Checkpointing 原始论文。
LoRA 与参数高效微调
- LoRA: Low-Rank Adaptation of Large Language Models — Hu et al., 2021.
- QLoRA: Efficient Finetuning of Quantized LLMs — Dettmers et al., 2023. 进一步将 base model 量化为 4-bit,是 LoRA 显存估算的极限形态。
MoE 训练
- Mixtral of Experts — Jiang et al., 2024. 现代 MoE 架构的代表性论文。
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity — Fedus et al., 2021. MoE 在 Transformer 中规模化的奠基论文,详细讨论了 Expert Parallelism 和 capacity factor。
- Tutel: Adaptive Mixture-of-Experts at Scale — Hwang et al., 2022. MoE All-to-All 通信优化,EP buffer 设计参考。
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model — DeepSeek-AI, 2024. MoE + GQA 组合的工程实践,与 Qwen3-30B-A3B 架构相近。
Qwen3 模型
- Qwen3 Technical Report — Qwen Team, Alibaba, 2025.
综合参考
- Transformer Math 101 — EleutherAI Blog. 系统整理了 Transformer 训练中各项显存和 FLOP 的计算公式,是本文公式体系的重要参考。
- Making Deep Learning Go Brrrr From First Principles — Horace He. 从 roofline model 角度分析显存带宽与计算的关系,有助于理解为什么 activation checkpointing 的时间代价是 30%。
- Efficient Large Scale Language Modeling with Mixtures of Experts — Artetxe et al., 2021.